[ ]:
%pip install torchvision
%pip install python-dotenv
Quantum Optical Reservoir Computing (QORC) on MNIST
This notebook walks you through a complete Quantum Optical Reservoir Computing (QORC) workflow applied to the MNIST handwritten-digit classification task, reproducing and extending the scheme introduced in:
Rambach et al. (2025) — Photonic Quantum-Accelerated Machine Learning, arXiv:2512.08318
Check out our live experiment! For this example, we removed the
wandbutilities from the notebook. You can still check the live experiment logs from March 18, 2026 on the project website: merlinquantum/webinar-merlin-for-hpc and watch the replay of the webinar given by Jean Senellart and Samuel Horsch.
What is QORC?
A reservoir computer is a fixed, non-linear dynamical system (the reservoir) whose rich internal dynamics project input data into a high-dimensional feature space. A simple, trainable readout layer then maps those features to the desired output.
In QORC (Rambach et al., 2025) the reservoir is a photonic quantum circuit:
Input data is encoded as phases in phase-shifters sandwiched between two random interferometers (the pre-circuit and the reservoir).
Boson sampling (or the quantum interference of \(N\) indistinguishable photons through \(M\) optical modes) produces an exponentially large output distribution that acts as a high-dimensional quantum fingerprint of the input.
Only a cheap linear readout is trained; the circuit itself is static and never optimised.
Figure to reproduce
The figure below (from Rambach et al., Fig. 5) illustrates the full QORC scheme that this notebook implements end-to-end:
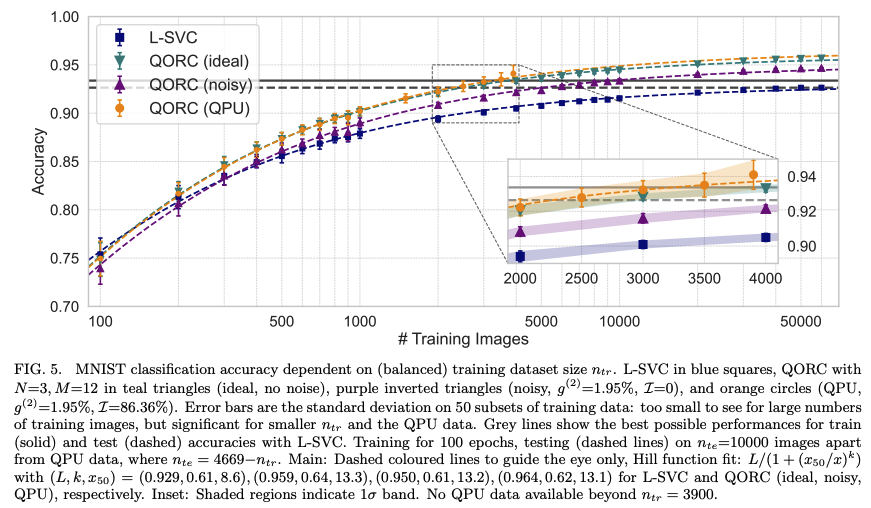
Figure — QORC scheme (Rambach et al., 2025, 2025). An input image is first processed by PCA to extract the top M components. These components set the phases in the encoding layer of a photonic circuit. Photons enter a random pre-circuit, traverse the phase-encoding layer, then a second random interferometer (reservoir). The resulting multi-photon coincidence distribution is combined with the original features and fed to a linear classifier.
Comments:
for 500 training samples, the QPU reservoir is obtaining better accuracy than the ideal reservoir and the L-SVC.
because training time constraints, we are only using 150 test samples and encourage you to run on more test samples for a more complete evaluation. This test set difference can explain the difference in results.
Workflow overview
Raw pixels (28×28)
│
▼
PCA (12 components) ←── dimensionality reduction
│
▼
Min-max scaling [0,1] ←── compatible with circuit angles
│
▼
Photonic Quantum Circuit (MerLin)
│
▼
Quantum feature vector Z ∈ ℝ^d
│
▼
Concatenate [pixels | Z]
│
▼
Linear readout (trained) → digit prediction
We compare three variants:
Model |
Reservoir |
Corresponds to |
|---|---|---|
L-SVC baseline |
no quantum features |
Rambach et al., input (i) |
MerLin ideal |
local (noiseless) quantum simulator |
Rambach et al., input (ii) |
MerLinProcessor |
remote photonic quantum processor (Ascella / Belenos) |
Rambach et al., QPU experiment |
0 · Setup
Imports
We use:
merlin— high-level library for building quantum ML layers on top of Perceval.perceval— Quandela’s photonic quantum computing framework.torch/torchvision— data loading and the linear readout model.scikit-learn— PCA, SVC, and metrics.
Reproducibility
All random seeds (Python, NumPy, PyTorch) are fixed up front so that every re-run produces exactly the same results.
Hyperparameters
Name |
Value |
Meaning |
|---|---|---|
|
50 |
Training samples per digit class |
|
10 |
Test samples per digit class |
|
12 |
PCA components → number of circuit inputs |
|
0.2 |
Fraction of training set held out for validation |
|
300 |
Training epochs for the linear readout |
|
1e-2 |
Adam learning-rate for the readout |
[20]:
from __future__ import annotations
import random
from pathlib import Path
import matplotlib.pyplot as plt
import numpy as np
import torch
import merlin as ML
import perceval as pcvl
from sklearn.metrics import accuracy_score, confusion_matrix
from sklearn.model_selection import train_test_split
from sklearn.decomposition import PCA
from sklearn.svm import LinearSVC
from torchvision.datasets import MNIST
# ---------------------------------------------------------------------------
# Hyperparameters
# ---------------------------------------------------------------------------
PER_CLASS_TRAIN = 50 # training samples per digit class
PER_CLASS_TEST = 20 # test samples per digit class
N_QFEATURES = 12 # PCA components (= number of circuit inputs)
VAL_FRACTION = 0.2 # held-out validation fraction
READOUT_EPOCHS = 300 # linear-readout training epochs
READOUT_LR = 2e-2 # Adam learning-rate
CONFUSION_LOG_EVERY = 25 # how often to export confusion matrices
# ---------------------------------------------------------------------------
# Reproducibility helpers
# ---------------------------------------------------------------------------
def reset_seeds(seed: int = 123) -> None:
"""Fix all random seeds so results are fully reproducible."""
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
def save_figure(fig: plt.Figure, out_path: Path) -> None:
"""Save a Matplotlib figure to disk and close it."""
out_path.parent.mkdir(parents=True, exist_ok=True)
fig.savefig(out_path, dpi=150, bbox_inches="tight")
plt.close(fig)
def make_mnist_samples_figure(
X_pixels: np.ndarray, y: np.ndarray, title: str
) -> plt.Figure:
fig, axes = plt.subplots(4, 4, figsize=(8, 8))
for i, ax in enumerate(axes.flat):
ax.imshow(X_pixels[i].reshape(28, 28), cmap="gray")
ax.set_title(f"Label: {int(y[i])}")
ax.axis("off")
fig.suptitle(title)
fig.tight_layout()
return fig
def make_pca_variance_figure(pca: PCA) -> plt.Figure:
fig, ax = plt.subplots(figsize=(7, 4))
ax.plot(
np.arange(1, len(pca.explained_variance_ratio_) + 1),
pca.explained_variance_ratio_,
marker="o",
)
ax.set_xlabel("Principal component")
ax.set_ylabel("Explained variance ratio")
ax.set_title("PCA explained variance")
ax.grid(True, alpha=0.3)
fig.tight_layout()
return fig
def make_pca_projection_figure(
X_pca: np.ndarray, y: np.ndarray, title: str
) -> plt.Figure:
fig, ax = plt.subplots(figsize=(7, 5))
scatter = ax.scatter(X_pca[:, 0], X_pca[:, 1], c=y, cmap="tab10", s=18, alpha=0.8)
ax.set_xlabel("PC1")
ax.set_ylabel("PC2")
ax.set_title(title)
cbar = fig.colorbar(scatter, ax=ax)
cbar.set_label("Digit")
fig.tight_layout()
return fig
def make_pca_components_figure(pca: PCA, n_components: int) -> plt.Figure:
ncols = 4
nrows = int(np.ceil(n_components / ncols))
fig, axes = plt.subplots(nrows, ncols, figsize=(10, 2.5 * nrows))
axes = np.atleast_1d(axes).reshape(nrows, ncols)
for idx, ax in enumerate(axes.flat):
if idx < n_components:
ax.imshow(pca.components_[idx].reshape(28, 28), cmap="coolwarm")
ax.set_title(f"PC{idx + 1}")
ax.axis("off")
else:
ax.axis("off")
fig.suptitle("PCA components")
fig.tight_layout()
return fig
def make_confusion_matrix_figure(
y_true: np.ndarray, y_pred: np.ndarray, title: str
) -> plt.Figure:
cm = confusion_matrix(y_true, y_pred, labels=np.arange(10))
fig, ax = plt.subplots(figsize=(7, 6))
im = ax.imshow(cm, cmap="Blues")
fig.colorbar(im, ax=ax)
ax.set_xlabel("Predicted")
ax.set_ylabel("True")
ax.set_title(title)
ax.set_xticks(np.arange(10))
ax.set_yticks(np.arange(10))
for i in range(cm.shape[0]):
for j in range(cm.shape[1]):
ax.text(
j, i, str(cm[i, j]), ha="center", va="center", color="black", fontsize=8
)
fig.tight_layout()
return fig
def export_circuit_description(reservoir: ML.QuantumLayer, output_dir: Path) -> Path:
output_dir.mkdir(parents=True, exist_ok=True)
out_path = output_dir / "reservoir_circuit.txt"
out_path.write_text(str(reservoir.circuit))
return out_path
def save_features_as_csv(
artifact_name: str,
output_dir: Path,
arrays: dict[str, tuple[np.ndarray, np.ndarray]],
) -> Path:
artifact_dir = output_dir / artifact_name
artifact_dir.mkdir(parents=True, exist_ok=True)
for name, (features, labels) in arrays.items():
features = np.asarray(features)
labels = np.asarray(labels).reshape(-1, 1)
if features.shape[0] == labels.shape[0]:
matrix = np.hstack([labels, features])
header = "label," + ",".join([f"f{i}" for i in range(features.shape[1])])
else:
matrix = features
header = ",".join([f"f{i}" for i in range(features.shape[1])])
np.savetxt(
artifact_dir / f"{name}.csv",
matrix,
delimiter=",",
header=header,
comments="",
)
return artifact_dir
def save_embeddings(output_dir: Path, embedding_dict: dict[str, np.ndarray]) -> Path:
output_dir.mkdir(parents=True, exist_ok=True)
out_path = output_dir / "embeddings.npz"
np.savez_compressed(out_path, **embedding_dict)
return out_path
reset_seeds(123)
print("All seeds fixed. Ready to go!")
All seeds fixed. Ready to go!
Local Outputs
This notebook now runs without external experiment-tracking utilities.
All generated artifacts (figures, CSV exports, circuit description, and embeddings) are saved locally in the output directory created below.
[3]:
# Output directory for local exports (figures, CSV features, circuit text, …)
output_dir = Path("./notebook_outputs")
output_dir.mkdir(parents=True, exist_ok=True)
#print(f"Local outputs will be saved in: {output_dir.resolve()}")
1 · Data — MNIST
Dataset
Stratified subsets
Quantum hardware and even simulators can be slow, so we keep the dataset deliberately small:
Training set:
PER_CLASS_TRAIN× 10 classes = 500 samplesTest set:
PER_CLASS_TEST× 10 classes = 100 samples
Stratification guarantees that every class is equally represented in both splits, which gives a fair accuracy estimate.
Exercise: Try increasing
PER_CLASS_TRAINto 100 and observe the effect on the classical baseline accuracy.
[4]:
def stratified_subset(
X: torch.Tensor, y: torch.Tensor, per_class: int, seed: int
) -> tuple[torch.Tensor, torch.Tensor]:
"""Return a balanced subset with exactly `per_class` samples per class."""
g = torch.Generator().manual_seed(seed)
indices = []
for cls in range(10):
cls_idx = torch.where(y == cls)[0]
perm = cls_idx[torch.randperm(len(cls_idx), generator=g)]
indices.append(perm[:per_class])
selected = torch.cat(indices)
selected = selected[torch.randperm(len(selected), generator=g)]
return X[selected], y[selected]
Let’s now load the dataset and build balanced train/test subsets.
[5]:
# Download (or load from cache) and preprocess MNIST
data_root = Path("./data")
train_ds = MNIST(root=data_root, train=True, download=True)
test_ds = MNIST(root=data_root, train=False, download=True)
X_train_full = train_ds.data.float().view(-1, 28 * 28) / 255.0 # (60000, 784)
y_train_full = train_ds.targets.long()
X_test_full = test_ds.data.float().view(-1, 28 * 28) / 255.0 # (10000, 784)
y_test_full = test_ds.targets.long()
# ── build stratified subsets ──
X_train, y_train = stratified_subset(
X_train_full, y_train_full, per_class=PER_CLASS_TRAIN, seed=123
)
X_test, y_test = stratified_subset(
X_test_full, y_test_full, per_class=PER_CLASS_TEST, seed=456
)
# Convert to NumPy for scikit-learn compatibility
X_train_pixels = X_train.numpy() # (500, 784)
y_train_np = y_train.numpy()
X_test_pixels = X_test.numpy() # (100, 784)
y_test_np = y_test.numpy()
print(
f"Training samples : {X_train_pixels.shape[0]} input dim = {X_train_pixels.shape[1]}"
)
print(
f"Test samples : {X_test_pixels.shape[0]} input dim = {X_test_pixels.shape[1]}"
)
Training samples : 500 input dim = 784
Test samples : 200 input dim = 784
[6]:
# ── Visualise a few training images ──
image_fig = make_mnist_samples_figure(
X_train_pixels[:16],
y_train_np[:16],
title="MNIST training sample preview",
)
plt.show()
save_figure(image_fig, output_dir / "figures" / "mnist_training_sample_preview.png")
# Save input datasets as local CSV files
save_features_as_csv(
artifact_name="mnist-selected-images",
output_dir=output_dir / "images",
arrays={
"X_train_pixels": (X_train_pixels, y_train_np),
"X_test_pixels": (X_test_pixels, y_test_np),
},
)
print("Sample images and CSV exports saved locally.")

Sample images and CSV exports saved locally.
2 · Classical Pre-processing — PCA + Min-Max Scaling
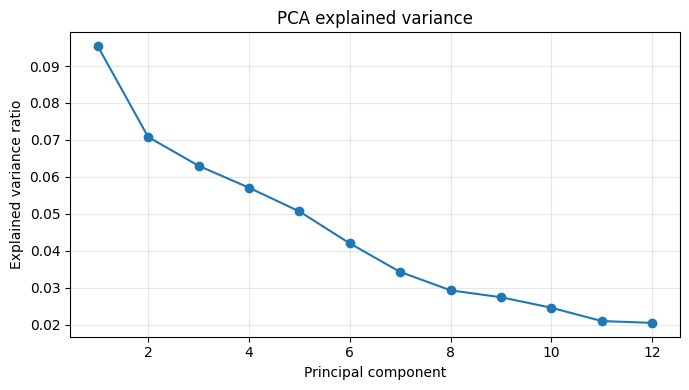
Why PCA?
N_QFEATURES = 12).Why min-max scaling?
x_scaled = (x - x_min) / (x_max - x_min + epsilon)Important: We transform the test set using statistics computed on the training set only to avoid data leakage.
Exercise: Try N_QFEATURES = 6 or 24. How does the explained variance change, and how does it affect downstream accuracy?
[7]:
def minmax_normalize(
data: np.ndarray, global_min: float, global_max: float
) -> np.ndarray:
"""Scale `data` to [0, 1] using pre-computed global min and max."""
epsilon = 1e-8
return (data - global_min) / (global_max - global_min + epsilon)
# ── Fit PCA on train, transform both splits ──
pca = PCA(n_components=N_QFEATURES, random_state=123)
X_train_pca = pca.fit_transform(X_train_pixels) # (500, 12)
X_test_pca = pca.transform(X_test_pixels) # (100, 12)
# ── Compute scaling statistics on train only ──
pca_global_min = X_train_pca.min()
pca_global_max = X_train_pca.max()
X_train_q = minmax_normalize(X_train_pca, pca_global_min, pca_global_max)
X_test_q = minmax_normalize(X_test_pca, pca_global_min, pca_global_max)
print(f"PCA output dim : {X_train_q.shape[1]}")
print(
f"Explained variance : {pca.explained_variance_ratio_.sum():.2%} ({N_QFEATURES} components)"
)
print(f"PCA global min/max : {pca_global_min:.4f} / {pca_global_max:.4f}")
print(f"X_train_q range : [{X_train_q.min():.4f}, {X_train_q.max():.4f}]")
PCA output dim : 12
Explained variance : 53.59% (12 components)
PCA global min/max : -5.3825 / 7.8062
X_train_q range : [0.0000, 1.0000]
[25]:
# ── Visualise PCA results ──
# 1. Screen plot — share of variance per component
fig_var = make_pca_variance_figure(pca)
plt.show()
save_figure(fig_var, output_dir / "figures" / "pca_explained_variance.png")
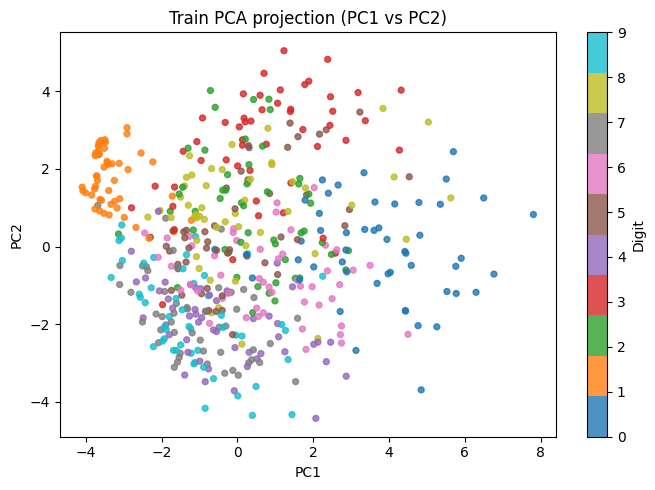
# 2. Scatter plot of the first two principal components (colour = class)
fig_proj = make_pca_projection_figure(
X_train_pca, y_train_np, "Train PCA projection (PC1 vs PC2)"
)
plt.show()
save_figure(fig_proj, output_dir / "figures" / "pca_train_projection_pc1_pc2.png")
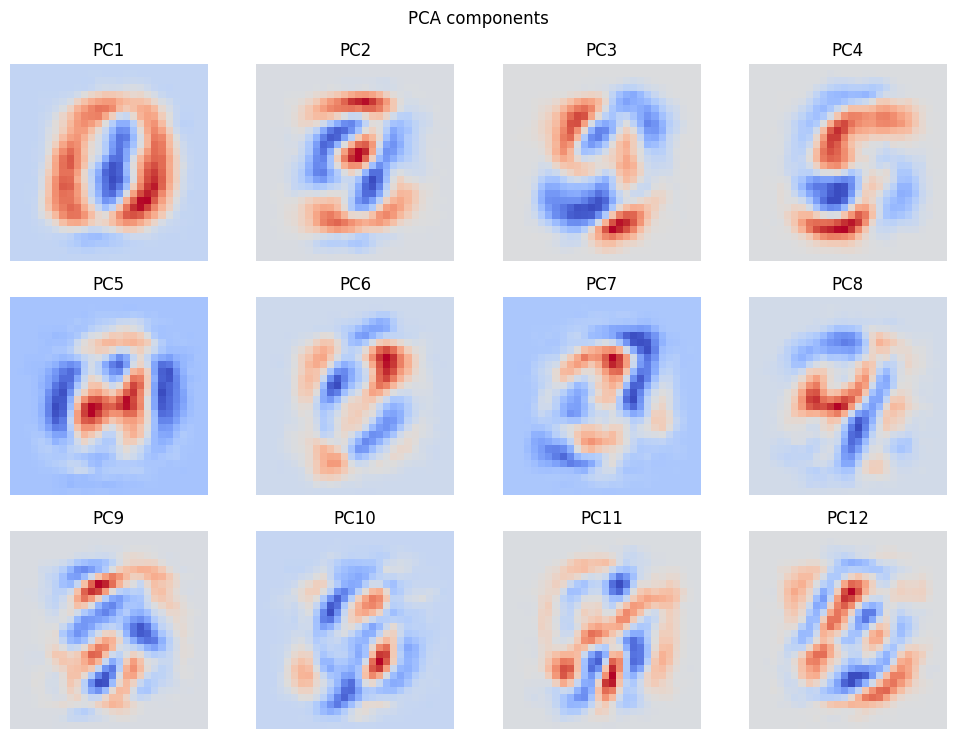
# 3. Spatial layout of each principal component (reshape to 28×28)
fig_comp = make_pca_components_figure(pca, n_components=N_QFEATURES)
plt.show()
save_figure(fig_comp, output_dir / "figures" / "pca_components.png")
3 · Classical Baseline — Linear SVC on Raw Pixels
Before introducing any quantum component it is essential to establish a classical baseline — a model with no quantum features.
What |
Value |
|---|---|
Model |
|
Input |
784-dim pixel vector |
Output |
digit 0–9 |
Note: L-SVC is a strong classifier for small datasets. Do not be surprised if the quantum model only matches — or slightly exceeds — it on 500 training samples.
[9]:
# ── Train L-SVC on raw pixels ──
baseline = LinearSVC(dual=False, random_state=123, max_iter=20_000)
baseline.fit(X_train_pixels, y_train_np)
baseline_preds = baseline.predict(X_test_pixels)
baseline_acc = accuracy_score(y_test_np, baseline_preds)
print(
f"L-SVC baseline accuracy : {baseline_acc:.4f} ({int(baseline_acc * len(y_test_np))}/{len(y_test_np)} correct)"
)
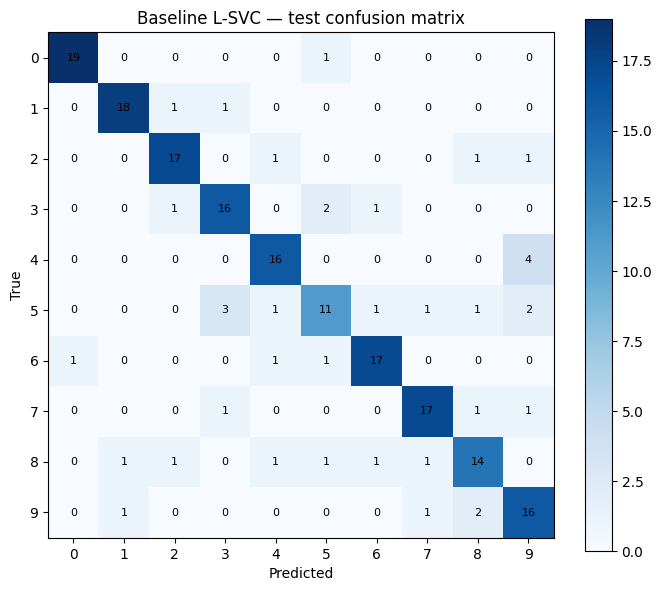
fig_cm_baseline = make_confusion_matrix_figure(
y_test_np, baseline_preds, "Baseline L-SVC — test confusion matrix"
)
plt.show()
save_figure(
fig_cm_baseline, output_dir / "figures" / "baseline_test_confusion_matrix.png"
)
L-SVC baseline accuracy : 0.8050 (161/200 correct)
4 · Building the Quantum Reservoir
Architecture overview
The circuit is built with MerLin’s ``CircuitBuilder`` and mirrors the architecture described in Rambach et al. (Fig. 1):
Input state → [Pre-circuit] → [Phase encoding] → [Reservoir] → Measurement
(entangling) (angle encoding) (entangling)
Paper name |
MerLin call |
Role |
|---|---|---|
Pre-circuit |
|
First fixed random interferometer — creates initial many-photon entanglement. |
Phase encoding |
|
Data-dependent phase shifters angles set to the PCA input values. This is how classical data enters the circuit. |
Reservoir |
|
Second fixed random interferometer — further mixes the photon amplitudes to produce a rich quantum fingerprint. |
Input state
The photons interfere through the circuit, and measuring the output photon distribution gives us a high-dimensional feature vector whose size grows combinatorially as \(\binom{N+M-1}{N}\).
Why is the reservoir fixed?
Note: The two random interferometers can in principle differ, but as Rambach et al. note, “for simplicity we have chosen them to be the same in all our experiments.” MerLin’s
add_entangling_layer()draws independent random parameters, so the two layers will generally differ here — which is equally valid.
[10]:
# ── Build the quantum reservoir circuit ──
#
# CircuitBuilder(n_modes=12) creates a 12-mode photonic circuit.
# The three layers are:
# 1. add_entangling_layer() — random beam-splitters (fixed weights)
# 2. add_angle_encoding() — data-dependent beam-splitter angles
# 3. add_entangling_layer() — another random entangling layer (fixed)
builder = ML.CircuitBuilder(n_modes=N_QFEATURES)
builder.add_entangling_layer()
builder.add_angle_encoding(modes=range(N_QFEATURES))
builder.add_entangling_layer()
# QuantumLayer wraps the circuit as a PyTorch-compatible module.
# input_state: Fock state with photons in modes 0, 2, 4
reservoir = ML.QuantumLayer(
builder=builder,
input_state=[1, 0, 1, 0, 1, 0] + ([0] * (N_QFEATURES - 6)),
).eval() # eval() → no gradient tracking, reservoir weights frozen
# Display the circuit schematic (Perceval renders it inline in the notebook)
pcvl.pdisplay(reservoir.circuit)
[10]:

[11]:
# ── Export circuit description locally ──
circuit_path = export_circuit_description(reservoir, output_dir / "circuit")
print(f"Circuit exported to: {circuit_path}")
Circuit exported to: notebook_outputs/circuit/reservoir_circuit.txt
5 · Extracting Quantum Features — Ideal Simulator
How it works
For each input sample \(\mathbf{x} \in [0,1]^{12}\):
The values of \(\mathbf{x}\) are loaded into the phase-encoding layer of the circuit.
The circuit is simulated exactly (no shot noise) on a classical computer using Perceval’s built-in permanent-based simulator.
The output probabilities of each Fock-basis measurement outcome form the quantum fingerprint \(\mathbf{z} \in \mathbb{R}^d\).
In Rambach et al.’s terminology, this is the “noiseless” / “ideal” simulation (the teal curve in their Fig. 5). The feature dimension \(d\) is the number of distinct multi-photon coincidence patterns, which grows combinatorially as \(\binom{N+M-1}{N}\): for N = 3 and M = 12, this gives d = 91 additional features.
Post-processing
Before feeding the quantum features to the readout, we:
Standardise them to zero mean and unit variance using training-set statistics: \(z_{\text{norm}} = \dfrac{z - \mu_{\text{train}}}{\sigma_{\text{train}} + \varepsilon}\)
Concatenate the normalised quantum features with the raw pixel vector: \(\mathbf{h} = [\mathbf{x}_{\text{pixels}} \;\|\; \mathbf{z}_{\text{norm}}]\)
The concatenation preserves all original information and lets the readout decide how much to weight the quantum enhancement. This corresponds to input (ii) QORC in Rambach et al. (Table 1).
[12]:
def as_numpy(x) -> np.ndarray:
"""Convert a tensor or array-like to a NumPy array."""
if isinstance(x, torch.Tensor):
return x.detach().cpu().numpy()
return np.asarray(x)
def standard_normalize(
data: np.ndarray, mean: np.ndarray, std: np.ndarray
) -> np.ndarray:
"""Zero-centre and unit-scale `data` with pre-computed train statistics."""
epsilon = 1e-8
return (data - mean) / (std + epsilon)
def extract_ideal_features(x_np: np.ndarray) -> np.ndarray:
"""Run the reservoir on CPU (ideal noiseless simulation)."""
with torch.no_grad():
z = reservoir(torch.tensor(x_np, dtype=torch.float32))
return as_numpy(z)
print("Running ideal (noiseless) quantum simulation …")
Z_train_ideal = extract_ideal_features(X_train_q) # (500, d_quantum)
Z_test_ideal = extract_ideal_features(X_test_q) # (100, d_quantum)
print(f"Quantum feature dim : {Z_train_ideal.shape[1]}")
print(f"Z_train_ideal shape : {Z_train_ideal.shape}")
print(f"Z_test_ideal shape : {Z_test_ideal.shape}")
# ── Save features as local CSV files ──
save_features_as_csv(
artifact_name="qorc-ideal-features",
output_dir=output_dir / "features",
arrays={
"Z_train_ideal": (Z_train_ideal, y_train_np),
"Z_test_ideal": (Z_test_ideal, y_test_np),
},
)
# ── Standardise and concatenate with raw pixels ──
qorc_mean_ideal = Z_train_ideal.mean(axis=0)
qorc_std_ideal = Z_train_ideal.std(axis=0)
Z_train_ideal_norm = standard_normalize(Z_train_ideal, qorc_mean_ideal, qorc_std_ideal)
Z_test_ideal_norm = standard_normalize(Z_test_ideal, qorc_mean_ideal, qorc_std_ideal)
# Final feature matrix: [raw pixels (784) | quantum features (d)]
X_train_ideal = np.concatenate([X_train_pixels, Z_train_ideal_norm], axis=1)
X_test_ideal = np.concatenate([X_test_pixels, Z_test_ideal_norm], axis=1)
print(f"Final feature dim (pixels + quantum) : {X_train_ideal.shape[1]}")
Running ideal (noiseless) quantum simulation …
Quantum feature dim : 220
Z_train_ideal shape : (500, 220)
Z_test_ideal shape : (200, 220)
Final feature dim (pixels + quantum) : 1004
6 · Training the Linear Readout
Why a linear readout?
The whole point of the reservoir approach is that only the readout is trained. By keeping it linear (a single nn.Linear layer), we demonstrate that the quantum reservoir is doing real work: any non-linear separation in the feature space must come from the circuit, not the classifier.
Training setup
Component |
Choice |
|---|---|
Architecture |
|
Loss |
Cross-entropy |
Optimiser |
Adam |
Epochs |
|
Learning rate |
|
A validation split (VAL_FRACTION = 0.2) is carved out of the training set to monitor over-fitting. Training/validation/test metrics and confusion matrices are printed and exported locally every CONFUSION_LOG_EVERY epochs.
[13]:
def train_linear_readout(
X_train: np.ndarray,
y_train: np.ndarray,
X_val: np.ndarray,
y_val: np.ndarray,
X_test: np.ndarray,
y_test: np.ndarray,
run_prefix: str,
n_epochs: int = READOUT_EPOCHS,
lr: float = READOUT_LR,
seed: int = 123,
confusion_every: int = CONFUSION_LOG_EVERY,
) -> tuple[np.ndarray, torch.nn.Linear]:
"""
Train a single linear layer (nn.Linear) as the readout classifier.
Parameters
----------
X_train / X_val / X_test : feature matrices
y_train / y_val / y_test : integer class labels
run_prefix : string prefix for output file names (e.g. 'ideal_readout')
n_epochs : number of gradient-descent steps
lr : Adam learning rate
seed : for weight initialisation reproducibility
confusion_every : export a confusion-matrix figure every N epochs
Returns
-------
final_preds : predicted class labels on the test set
model : trained nn.Linear module
"""
torch.manual_seed(seed)
n_features = X_train.shape[1]
model = torch.nn.Linear(n_features, 10)
optimiser = torch.optim.Adam(model.parameters(), lr=lr)
loss_fn = torch.nn.CrossEntropyLoss()
# Convert to tensors once
X_train_t = torch.tensor(X_train, dtype=torch.float32)
y_train_t = torch.tensor(y_train, dtype=torch.long)
X_val_t = torch.tensor(X_val, dtype=torch.float32)
y_val_t = torch.tensor(y_val, dtype=torch.long)
X_test_t = torch.tensor(X_test, dtype=torch.float32)
for epoch in range(1, n_epochs + 1):
# ── forward + backward pass ──
model.train()
optimiser.zero_grad()
train_logits = model(X_train_t)
train_loss = loss_fn(train_logits, y_train_t)
train_loss.backward()
optimiser.step()
# ── evaluation (no gradients needed) ──
model.eval()
with torch.no_grad():
val_logits = model(X_val_t)
val_loss = loss_fn(val_logits, y_val_t)
test_logits = model(X_test_t)
train_preds = train_logits.argmax(dim=1).cpu().numpy()
val_preds = val_logits.argmax(dim=1).cpu().numpy()
test_preds = test_logits.argmax(dim=1).cpu().numpy()
train_acc = accuracy_score(y_train, train_preds)
val_acc = accuracy_score(y_val, val_preds)
test_acc = accuracy_score(y_test, test_preds)
if epoch % 25 == 0 or epoch == 1 or epoch == n_epochs:
print(
f"[{run_prefix}] epoch {epoch:03d} | "
f"train_loss={train_loss.item():.4f} val_loss={val_loss.item():.4f} | "
f"train_acc={train_acc:.4f} val_acc={val_acc:.4f} test_acc={test_acc:.4f}"
)
# ── periodic confusion-matrix export ──
if epoch % confusion_every == 0 or epoch == 1 or epoch == n_epochs:
cm_fig = make_confusion_matrix_figure(
y_true=y_test,
y_pred=test_preds,
title=f"{run_prefix} — test confusion matrix (epoch {epoch})",
)
save_figure(
cm_fig,
output_dir
/ "figures"
/ f"{run_prefix}_test_confusion_matrix_epoch_{epoch:03d}.png",
)
# ── final predictions ──
model.eval()
with torch.no_grad():
final_preds = model(X_test_t).argmax(dim=1).cpu().numpy()
return final_preds, model
print("train_linear_readout() defined.")
train_linear_readout() defined.
[21]:
# ── Split training set into train / validation ──
X_train_ideal_fit, X_val_ideal, y_train_ideal_fit, y_val_ideal = train_test_split(
X_train_ideal,
y_train_np,
test_size=VAL_FRACTION,
random_state=123,
stratify=y_train_np,
)
print(f"Train split : {X_train_ideal_fit.shape[0]} samples")
print(f"Val split : {X_val_ideal.shape[0]} samples")
print(f"Feature dim : {X_train_ideal_fit.shape[1]}")
print("Training linear readout on ideal quantum features")
ideal_preds, ideal_model = train_linear_readout(
X_train=X_train_ideal_fit,
y_train=y_train_ideal_fit,
X_val=X_val_ideal,
y_val=y_val_ideal,
X_test=X_test_ideal,
y_test=y_test_np,
run_prefix="ideal_readout",
seed=123,
)
ideal_acc = accuracy_score(y_test_np, ideal_preds)
ideal_model_params = int(sum(p.numel() for p in ideal_model.parameters()))
print(
f"MerLin ideal accuracy : {ideal_acc:.4f} ({int(ideal_acc * len(y_test_np))}/{len(y_test_np)} correct)"
)
print(f"Ideal model parameters: {ideal_model_params}")
Train split : 400 samples
Val split : 100 samples
Feature dim : 1004
Training linear readout on ideal quantum features
[ideal_readout] epoch 001 | train_loss=2.2164 val_loss=1.3236 | train_acc=0.2100 val_acc=0.6000 test_acc=0.6450
[ideal_readout] epoch 025 | train_loss=0.0705 val_loss=0.7815 | train_acc=0.9850 val_acc=0.8200 test_acc=0.7950
[ideal_readout] epoch 050 | train_loss=0.0187 val_loss=0.7968 | train_acc=1.0000 val_acc=0.8000 test_acc=0.7900
[ideal_readout] epoch 075 | train_loss=0.0113 val_loss=0.8293 | train_acc=1.0000 val_acc=0.8000 test_acc=0.7950
[ideal_readout] epoch 100 | train_loss=0.0083 val_loss=0.8454 | train_acc=1.0000 val_acc=0.8000 test_acc=0.7850
[ideal_readout] epoch 125 | train_loss=0.0066 val_loss=0.8583 | train_acc=1.0000 val_acc=0.8000 test_acc=0.7900
[ideal_readout] epoch 150 | train_loss=0.0053 val_loss=0.8690 | train_acc=1.0000 val_acc=0.8000 test_acc=0.7900
[ideal_readout] epoch 175 | train_loss=0.0045 val_loss=0.8791 | train_acc=1.0000 val_acc=0.8100 test_acc=0.7900
[ideal_readout] epoch 200 | train_loss=0.0038 val_loss=0.8885 | train_acc=1.0000 val_acc=0.8100 test_acc=0.7900
[ideal_readout] epoch 225 | train_loss=0.0033 val_loss=0.8973 | train_acc=1.0000 val_acc=0.8100 test_acc=0.7900
[ideal_readout] epoch 250 | train_loss=0.0028 val_loss=0.9056 | train_acc=1.0000 val_acc=0.8100 test_acc=0.7900
[ideal_readout] epoch 275 | train_loss=0.0025 val_loss=0.9134 | train_acc=1.0000 val_acc=0.8100 test_acc=0.7900
[ideal_readout] epoch 300 | train_loss=0.0022 val_loss=0.9207 | train_acc=1.0000 val_acc=0.8100 test_acc=0.7900
MerLin ideal accuracy : 0.7900 (158/200 correct)
Ideal model parameters: 10050
7 · (Optional) Remote Quantum Processor — MerLinProcessor
What changes?
Instead of the local noiseless simulator, we now forward the data through a real (or noise-model) remote photonic processor hosted by Quandela Cloud.
MerlinProcessor handles:
Batching: splits the dataset into micro-batches to respect API rate limits.
Shot noise: real hardware produces probabilistic measurement outcomes; the feature vectors are now averages over
max_shots_per_callshots.Timeouts & retries: configurable via
timeoutandchunk_concurrency.
The processor features are then standardised and concatenated with raw pixels, exactly as in the ideal run.
Obtaining a cloud token
Register at cloud.quandela.com.
Create a
.envfile in this folder containing:CLOUD_TOKEN=your_token_here
Re-run the cell below — it will pick up the token automatically.
Skip: if
CLOUD_TOKENis not set, this section is silently skipped and the final comparison table shows “N/A” for the processor row.
[ ]:
"""
Utility for loading the Quandela cloud token from a .env file or
from the environment.
Supported .env variable names (checked in this order):
CLOUD_TOKEN
QUANDELA_CLOUD_TOKEN
QUANDELA_TOKEN
Fallback: if none of those keys are found, the file is scanned for a
raw token line (i.e. a non-empty line that contains no '=' sign and
is not a comment).
Recommended .env format:
CLOUD_TOKEN=your_token_here
"""
import os
from pathlib import Path
from dotenv import load_dotenv
# Paths to search for a .env file, tried in order.
_ENV_SEARCH_PATHS = [
Path(".env"),
Path("Quantum_Machine_Learning-MerLin/.env"),
]
def load_cloud_token() -> str:
"""Return the Quandela cloud token as a string (empty string if not found).
The function:
1. Loads every .env file it can find into the process environment.
2. Checks standard environment-variable names for the token.
3. Falls back to reading a raw (key-less) token line from the .env file.
"""
# Step 1 – load all .env files that exist on disk.
found_env_files = []
for path in _ENV_SEARCH_PATHS:
if path.exists():
load_dotenv(dotenv_path=path, override=False)
found_env_files.append(str(path))
# Step 2 – check well-known environment-variable names.
token = (
os.getenv("CLOUD_TOKEN")
or os.getenv("QUANDELA_CLOUD_TOKEN")
or os.getenv("QUANDELA_TOKEN")
or ""
).strip()
# Step 3 – fallback for .env files that contain only a bare token string.
if not token:
for path in _ENV_SEARCH_PATHS:
if not path.exists():
continue
for line in path.read_text(encoding="utf-8", errors="ignore").splitlines():
stripped = line.strip()
# Skip blank lines and comment lines.
if not stripped or stripped.startswith("#"):
continue
# A line with no '=' is treated as a raw token.
if "=" not in stripped:
token = stripped
break
if token:
break
if not token:
searched = found_env_files or [str(p) for p in _ENV_SEARCH_PATHS]
print("[token_utils] Cloud token not found.")
print(f"[token_utils] Searched: {searched}")
print("[token_utils] Expected .env format: CLOUD_TOKEN=your_token_here")
return token
[ ]:
CLOUD_TOKEN = load_cloud_token()
processor_acc = None # will be filled in if token is available
# Collect all embeddings for the final .npz artifact
embeddings_payload: dict[str, np.ndarray] = {
"X_train_pixels": X_train_pixels,
"X_test_pixels": X_test_pixels,
"X_train_pca": X_train_pca,
"X_test_pca": X_test_pca,
"X_train_q": X_train_q,
"X_test_q": X_test_q,
"Z_train_ideal": Z_train_ideal,
"Z_test_ideal": Z_test_ideal,
"Z_train_ideal_norm": Z_train_ideal_norm,
"Z_test_ideal_norm": Z_test_ideal_norm,
"y_train": y_train_np,
"y_test": y_test_np,
}
if not CLOUD_TOKEN:
print("MerLinProcessor run skipped – set CLOUD_TOKEN in your .env file.")
else:
print("Connecting to remote quantum processor (sim:belenos) …")
pcvl.RemoteConfig.set_token(CLOUD_TOKEN)
remote_processor = pcvl.RemoteProcessor("sim:ascella")
print("Connection established.")
# ── MerlinProcessor wraps the remote backend ──
proc = ML.MerlinProcessor(
remote_processor,
microbatch_size=32, # samples per API call
timeout=3600.0, # max seconds to wait for a batch
max_shots_per_call=100,
chunk_concurrency=1,
)
x_train_q_t = torch.tensor(X_train_q, dtype=torch.float32)
x_test_q_t = torch.tensor(X_test_q, dtype=torch.float32)
print(
f"Sending training data ({X_train_q.shape[0]} samples) to the quantum processor …"
)
Z_train_proc = as_numpy(proc.forward(reservoir, x_train_q_t))
print("Training data retrieved.")
print(f"Sending test data ({X_test_q.shape[0]} samples) to the quantum processor …")
Z_test_proc = as_numpy(proc.forward(reservoir, x_test_q_t))
print("Test data retrieved.")
save_features_as_csv(
artifact_name="qorc-processor-features",
output_dir=output_dir / "features",
arrays={
"Z_train_proc": (Z_train_proc, y_train_np),
"Z_test_proc": (Z_test_proc, y_test_np),
},
)
# ── Standardise and concatenate with pixels ──
print("Normalising processor quantum features …")
qorc_mean_proc = Z_train_proc.mean(axis=0)
qorc_std_proc = Z_train_proc.std(axis=0)
Z_train_proc_norm = standard_normalize(Z_train_proc, qorc_mean_proc, qorc_std_proc)
Z_test_proc_norm = standard_normalize(Z_test_proc, qorc_mean_proc, qorc_std_proc)
X_train_proc = np.concatenate([X_train_pixels, Z_train_proc_norm], axis=1)
X_test_proc = np.concatenate([X_test_pixels, Z_test_proc_norm], axis=1)
X_train_proc_fit, X_val_proc, y_train_proc_fit, y_val_proc = train_test_split(
X_train_proc,
y_train_np,
test_size=VAL_FRACTION,
random_state=123,
stratify=y_train_np,
)
print("Training linear readout on processor features …")
proc_preds, proc_model = train_linear_readout(
X_train=X_train_proc_fit,
y_train=y_train_proc_fit,
X_val=X_val_proc,
y_val=y_val_proc,
X_test=X_test_proc,
y_test=y_test_np,
run_prefix="processor_readout",
seed=123,
)
processor_acc = accuracy_score(y_test_np, proc_preds)
processor_model_params = int(sum(p.numel() for p in proc_model.parameters()))
print(f"MerLinProcessor accuracy : {processor_acc:.4f}")
print(f"Processor model parameters: {processor_model_params}")
embeddings_payload.update({
"Z_train_processor": Z_train_proc,
"Z_test_processor": Z_test_proc,
"Z_train_processor_norm": Z_train_proc_norm,
"Z_test_processor_norm": Z_test_proc_norm,
})
Training linear readout on processor features …
[processor_readout] epoch 001 | train_loss=2.3107 val_loss=1.8873 | train_acc=0.0775 val_acc=0.5300 test_acc=0.5250
[processor_readout] epoch 025 | train_loss=0.1496 val_loss=0.6780 | train_acc=0.9850 val_acc=0.8000 test_acc=0.7950
[processor_readout] epoch 050 | train_loss=0.0480 val_loss=0.6680 | train_acc=1.0000 val_acc=0.8100 test_acc=0.7950
[processor_readout] epoch 075 | train_loss=0.0283 val_loss=0.6641 | train_acc=1.0000 val_acc=0.8000 test_acc=0.7900
[processor_readout] epoch 100 | train_loss=0.0201 val_loss=0.6736 | train_acc=1.0000 val_acc=0.8000 test_acc=0.7900
[processor_readout] epoch 125 | train_loss=0.0153 val_loss=0.6845 | train_acc=1.0000 val_acc=0.8100 test_acc=0.8050
[processor_readout] epoch 150 | train_loss=0.0122 val_loss=0.6946 | train_acc=1.0000 val_acc=0.8000 test_acc=0.8050
[processor_readout] epoch 175 | train_loss=0.0100 val_loss=0.7042 | train_acc=1.0000 val_acc=0.8000 test_acc=0.8050
[processor_readout] epoch 200 | train_loss=0.0084 val_loss=0.7133 | train_acc=1.0000 val_acc=0.8000 test_acc=0.8050
[processor_readout] epoch 225 | train_loss=0.0072 val_loss=0.7218 | train_acc=1.0000 val_acc=0.8000 test_acc=0.8100
[processor_readout] epoch 250 | train_loss=0.0062 val_loss=0.7299 | train_acc=1.0000 val_acc=0.8000 test_acc=0.8100
[processor_readout] epoch 275 | train_loss=0.0055 val_loss=0.7375 | train_acc=1.0000 val_acc=0.8000 test_acc=0.8100
[processor_readout] epoch 300 | train_loss=0.0048 val_loss=0.7448 | train_acc=1.0000 val_acc=0.8000 test_acc=0.8050
MerLinProcessor accuracy : 0.8050
Processor model parameters: 10050
8 · Results & Comparison
We collect all three accuracy scores into a summary table and save it locally.
After this cell:
All intermediate embeddings (pixel features, PCA projections, quantum features) are saved locally as an
.npzfile.A local CSV summary table is created for the three runs.
Interpreting the results
Model |
Reservoir |
Typical behaviour on small subsets |
Paper reference |
|---|---|---|---|
L-SVC baseline |
none |
Strong classical reference |
Rambach et al., Table 1 row (i) |
MerLin ideal |
noiseless sim |
Can be above, similar to, or slightly below baseline on a single small split; variance across seeds/subsets can dominate |
Table 1 row (ii): +4% test accuracy on full MNIST |
MerLinProcessor |
photonic hardware |
Often close to ideal; hardware noise may lower accuracy, but parity with baseline is possible on small benchmarks |
Fig. 5 (orange): QPU matches ideal within error bars |
Run-level takeaway (this notebook): L-SVC and MerLinProcessor are tied at 0.8050, while MerLin ideal is 0.7900 (−1.5 percentage points vs baseline). Because this evaluation uses only 200 test samples, these gaps should be treated as indicative rather than conclusive. The paper reports trends on larger evaluations and repeated experiments; this notebook is primarily for reproducing the end-to-end pipeline hands-on.
[23]:
# ── Save all embeddings as a compressed .npz artifact ──
embeddings_path = save_embeddings(
output_dir=output_dir, embedding_dict=embeddings_payload
)
# ── Build results table and save locally ──
rows = [
["L-SVC baseline", float(baseline_acc)],
["MerLin ideal (local sim)", float(ideal_acc)],
[
"MerLinProcessor (remote)",
None if processor_acc is None else float(processor_acc),
],
]
results_lines = ["run,accuracy"]
for run_name, acc in rows:
value = "" if acc is None else f"{acc:.6f}"
results_lines.append(f"{run_name},{value}")
results_path = output_dir / "results_accuracy.csv"
results_path.parent.mkdir(parents=True, exist_ok=True)
results_path.write_text("\n".join(results_lines) + "\n")
# ── Print summary ──
n_test = len(y_test_np)
ideal_delta = ideal_acc - baseline_acc
print("=" * 55)
print(" Accuracy comparison")
print("=" * 55)
print(f" L-SVC baseline : {baseline_acc:.4f}")
print(f" MerLin ideal (local sim) : {ideal_acc:.4f}")
print(f" Δ ideal - baseline : {ideal_delta:+.4f}")
if processor_acc is None:
print(" MerLinProcessor : skipped (no CLOUD_TOKEN)")
else:
proc_delta = processor_acc - baseline_acc
print(f" MerLinProcessor (hardware) : {processor_acc:.4f}")
print(f" Δ hardware - baseline : {proc_delta:+.4f}")
print("=" * 55)
print(f"Note: evaluation is based on n_test={n_test} samples; interpret small gaps with caution.")
print(f"Embeddings saved to: {embeddings_path}")
print(f"Results table saved to: {results_path}")
=======================================================
Accuracy comparison
=======================================================
L-SVC baseline : 0.8050
MerLin ideal (local sim) : 0.7900
MerLinProcessor (hardware) : 0.8050
=======================================================
Embeddings saved to: notebook_outputs/embeddings.npz
Results table saved to: notebook_outputs/results_accuracy.csv
9 · Going Further
Exercises
More data: Increase
PER_CLASS_TRAINto 100 or 200. Does the quantum advantage grow? Rambach et al. (Fig. 5) show QORC surpasses peak L-SVC accuracy with ~20× fewer training images.Fewer PCA components: Try
N_QFEATURES = 6. How much variance is lost, and how does accuracy change?Different input states: Change the Fock input state to
[1,1,0,0,…](two adjacent photons). How does interference change the features? Rambach et al. (Supplemental Sec. S4) explore different \(N\) and input states.More entangling layers: Add a third
builder.add_entangling_layer(). Does the reservoir become richer?Remove pixel concatenation: Train the readout on quantum features only (remove
X_train_pixelsfrom the concatenation). Rambach et al. (Table 1, row iii) find that reservoir-only features still beat the baseline.SVC readout: Replace
nn.LinearwithLinearSVC. Do you get a different accuracy / training time trade-off?Photon indistinguishability: Rambach et al. (Fig. 3) show that QORC remains advantageous even for fully distinguishable photons (\(\mathcal{I}=0\)) due to first-order quantum coherence. Explore this by adding noise to the simulator if MerLin supports it.
Further reading
Rambach et al., 2025* (2025) — Photonic Quantum-Accelerated Machine Learning, arXiv:2512.08318 — the paper this notebook reproduces;
Sakurai *et al* (2025) — Quantum Optical Reservoir Computing, — the original QORC proposal;
Mujal et al. (2021) — Opportunities in Quantum Reservoir Computing and Extreme Learning Machines;
Perceval documentation: perceval.quandela.net;
MerLin documentation: merlinquantum.ai;
Other tutorials: Tutorials by Quandela.