merlin.algorithms.layer module
Main QuantumLayer implementation
- class merlin.algorithms.layer.QuantumLayer(input_size=None, builder=None, circuit=None, experiment=None, input_state=None, n_photons=None, trainable_parameters=None, input_parameters=None, amplitude_encoding=False, computation_space=None, measurement_strategy=None, return_object=False, device=None, dtype=None)
Bases:
MerlinModuleQuantum neural network layer with factory-based architecture.
This layer can be created either from a
CircuitBuilderinstance, a pre-compiledpcvl.Circuit, or anpcvl.Experiment.- export_config()
Export a standalone configuration for remote execution.
- Returns:
Serializable layer configuration containing the resolved circuit, parameters, and input metadata.
- Return type:
- forward(*input_parameters, shots=None, sampling_method=None, simultaneous_processes=None)
Forward pass through the quantum layer.
Encoding is inferred from the input type:
torch.Tensor(float): angle encoding (compatible withnn.Sequential)torch.Tensor(complex): amplitude encodingStateVector: amplitude encoding (preferred for quantum state injection)
- Parameters:
input_parameters (torch.Tensor | merlin.core.state_vector.StateVector) – Input data. For angle encoding, pass float tensors. For amplitude encoding, pass a single
StateVectoror complex tensor.shots (int | None) – Number of samples; if 0 or None, return exact amplitudes/probabilities.
sampling_method (str | None) – Sampling method, e.g. “multinomial”.
simultaneous_processes (int | None) – Batch size hint for parallel computation.
- Returns:
Output after measurement mapping. Depending on the return_object argument and measurement strategy defined in the input, the output type will be different. Check the constructor for more details.
- Return type:
torch.Tensor | PartialMeasurement | merlin.core.state_vector.StateVector | ProbabilityDistribution
- Raises:
TypeError – If inputs mix
torch.TensorandStateVector, or if an unsupported input type is provided.ValueError – If multiple
StateVectorinputs are provided.
- property has_custom_detectors: bool
Whether the wrapped experiment defines non-default detectors.
- Type:
- property output_keys
Return the Fock basis associated with the layer outputs.
- prepare_parameters(input_parameters)
Prepare parameter list for circuit evaluation.
- set_input_state(input_state)
Set the layer input state for subsequent evaluations.
- Parameters:
input_state (pcvl.BasicState | tuple | list | torch.Tensor | merlin.core.state_vector.StateVector) – Input state to store on the layer and underlying computation process.
- set_sampling_config(shots=None, sampling_method=None)
Deprecated: sampling configuration must be provided at call time in forward.
- classmethod simple(cls, input_size, output_size=None, device=None, dtype=None, computation_space=ComputationSpace.UNBUNCHED)
Create a ready-to-train layer with a (input_size+1)-mode, ceil((input_size+1)/2)-photon architecture.
The circuit is assembled via
CircuitBuilderwith the following layout:A fully trainable entangling layer acting on all modes;
A full input encoding layer spanning all encoded features;
A fully trainable entangling layer acting on all modes.
- Parameters:
input_size (int) – Size of the classical input vector. Must be 19 or lower.
output_size (int | None) – Optional classical output width.
device (torch.device | None) – Optional target device for tensors.
dtype (torch.dtype | None) – Optional tensor dtype.
computation_space (ComputationSpace | str) – Logical computation subspace; one of
{"fock", "unbunched", "dual_rail"}.
- Returns:
QuantumLayer configured with the described architecture.
- Return type:
- to(*args, **kwargs)
Move the layer and auxiliary transforms to a new device or dtype.
- Parameters:
*args – Positional arguments forwarded to
torch.nn.Module.to().**kwargs – Keyword arguments forwarded to
torch.nn.Module.to().
- Returns:
The updated layer instance.
- Return type:
Note
Quantum layers built from a pcvl.Experiment now apply the experiment’s per-mode detector configuration before returning classical outputs. When no detectors are specified, ideal photon-number resolving detectors are used by default.
If the experiment carries a pcvl.NoiseModel (via experiment.noise), MerLin inserts a PhotonLossTransform ahead of any detector transform. The resulting output_keys and output_size therefore include every survival/loss configuration implied by the model, and amplitude read-out is disabled whenever custom detectors or photon loss are present.
Example: Quickstart QuantumLayer
import torch.nn as nn
from merlin import QuantumLayer
simple_layer = QuantumLayer.simple(
input_size=4,
)
model = nn.Sequential(
simple_layer,
nn.Linear(simple_layer.output_size, 3),
)
# Train and evaluate as a standard torch.nn.Module
Note
QuantumLayer.simple() returns a thin SimpleSequential wrapper that behaves like a standard
PyTorch module while exposing the inner quantum layer as .quantum_layer and any
post-processing (ModGrouping or Identity) as .post_processing.
The wrapper also forwards .circuit and .output_size so existing code that inspects these
attributes continues to work.
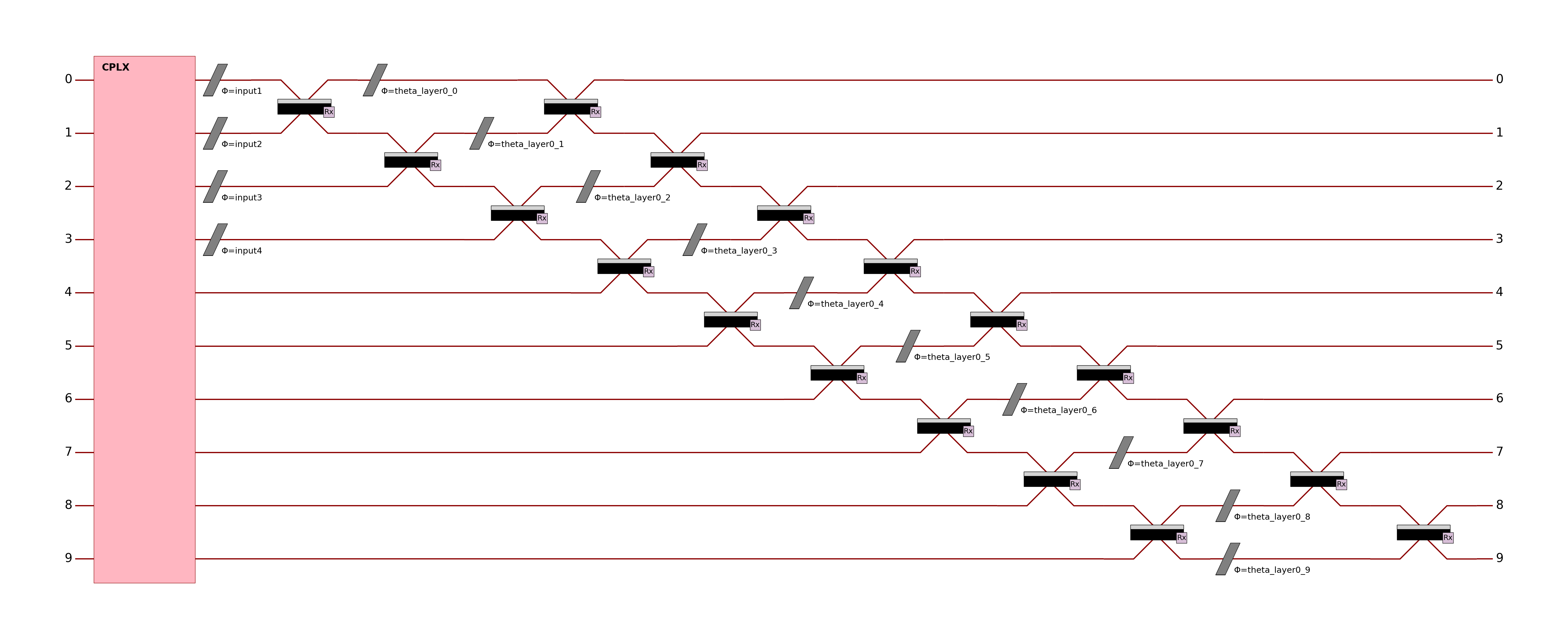
The simple quantum layer above implements a circuit of (input_size+1) modes and (ceil((input_size+1)/2)) photons. This circuit is made of: - A fully trainable entangling layer acting on all modes; - A full input encoding layer spanning all encoded features; - A fully trainable entangling layer acting on all modes.
Example: Declarative builder API
import torch.nn as nn
from merlin import LexGrouping, MeasurementStrategy, QuantumLayer
from merlin.builder import CircuitBuilder
builder = CircuitBuilder(n_modes=6)
builder.add_entangling_layer(trainable=True, name="U1")
builder.add_angle_encoding(modes=list(range(4)), name="input")
builder.add_rotations(trainable=True, name="theta")
builder.add_superpositions(depth=1)
builder_layer = QuantumLayer(
input_size=4,
builder=builder,
n_photons=3, # is equivalent to input_state=[1,1,1,0,0,0]
measurement_strategy=MeasurementStrategy.probs(),
)
model = nn.Sequential(
builder_layer,
LexGrouping(builder_layer.output_size, 3),
)
# Train and evaluate as a standard torch.nn.Module
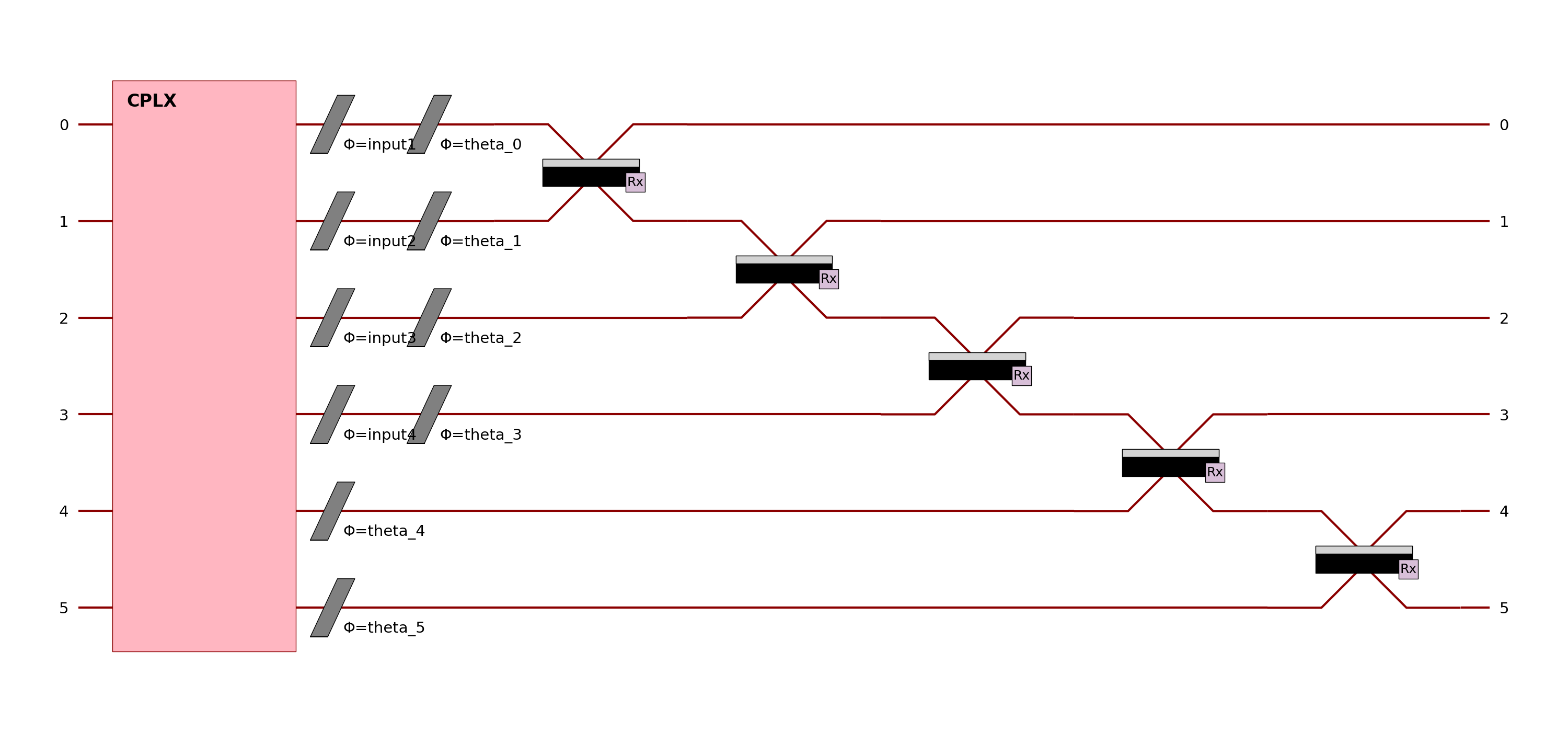
The circuit builder allows you to build your circuit layer by layer, with a high-level API. The example above implements a circuit of 6 modes and 3 photons. This circuit is made of: - A first entangling layer (trainable) - Angle encoding on the first 4 modes (for 4 input parameters with the name “input”) - A trainable rotation layer to add more trainable parameters - An entangling layer to add more expressivity
Other building blocks in the CircuitBuilder include:
add_rotations: Add single or multiple phase shifters (rotations) to specific modes. Rotations can be fixed, trainable, or data-driven (input-encoded).
add_angle_encoding: Encode classical data as quantum rotation angles, supporting higher-order feature combinations for expressive input encoding.
add_entangling_layer: Insert a multi-mode entangling layer (implemented via a generic interferometer), optionally trainable, and tune its internal template with the
modelargument ("mzi"or"bell") for different mixing behaviours.add_superpositions: Add one or more beam splitters (superposition layers) with configurable targets, depth, and trainability.
Example: Manual Perceval circuit (more control)
import torch.nn as nn
import perceval as pcvl
from merlin import LexGrouping, MeasurementStrategy, QuantumLayer
modes = 6
wl = pcvl.GenericInterferometer(
modes,
lambda i: pcvl.BS() // pcvl.PS(pcvl.P(f"theta_li{i}")) //
pcvl.BS() // pcvl.PS(pcvl.P(f"theta_lo{i}")),
shape=pcvl.InterferometerShape.RECTANGLE,
)
circuit = pcvl.Circuit(modes)
circuit.add(0, wl)
for mode in range(4):
circuit.add(mode, pcvl.PS(pcvl.P(f"input{mode}")))
wr = pcvl.GenericInterferometer(
modes,
lambda i: pcvl.BS() // pcvl.PS(pcvl.P(f"theta_ri{i}")) //
pcvl.BS() // pcvl.PS(pcvl.P(f"theta_ro{i}")),
shape=pcvl.InterferometerShape.RECTANGLE,
)
circuit.add(0, wr)
manual_layer = QuantumLayer(
input_size=4, # matches the number of phase shifters named "input{mode}"
circuit=circuit,
input_state=[1, 0, 1, 0, 1, 0],
trainable_parameters=["theta"],
input_parameters=["input"],
measurement_strategy=MeasurementStrategy.probs(),
)
model = nn.Sequential(
manual_layer,
LexGrouping(manual_layer.output_size, 3),
)
# Train and evaluate as a standard torch.nn.Module
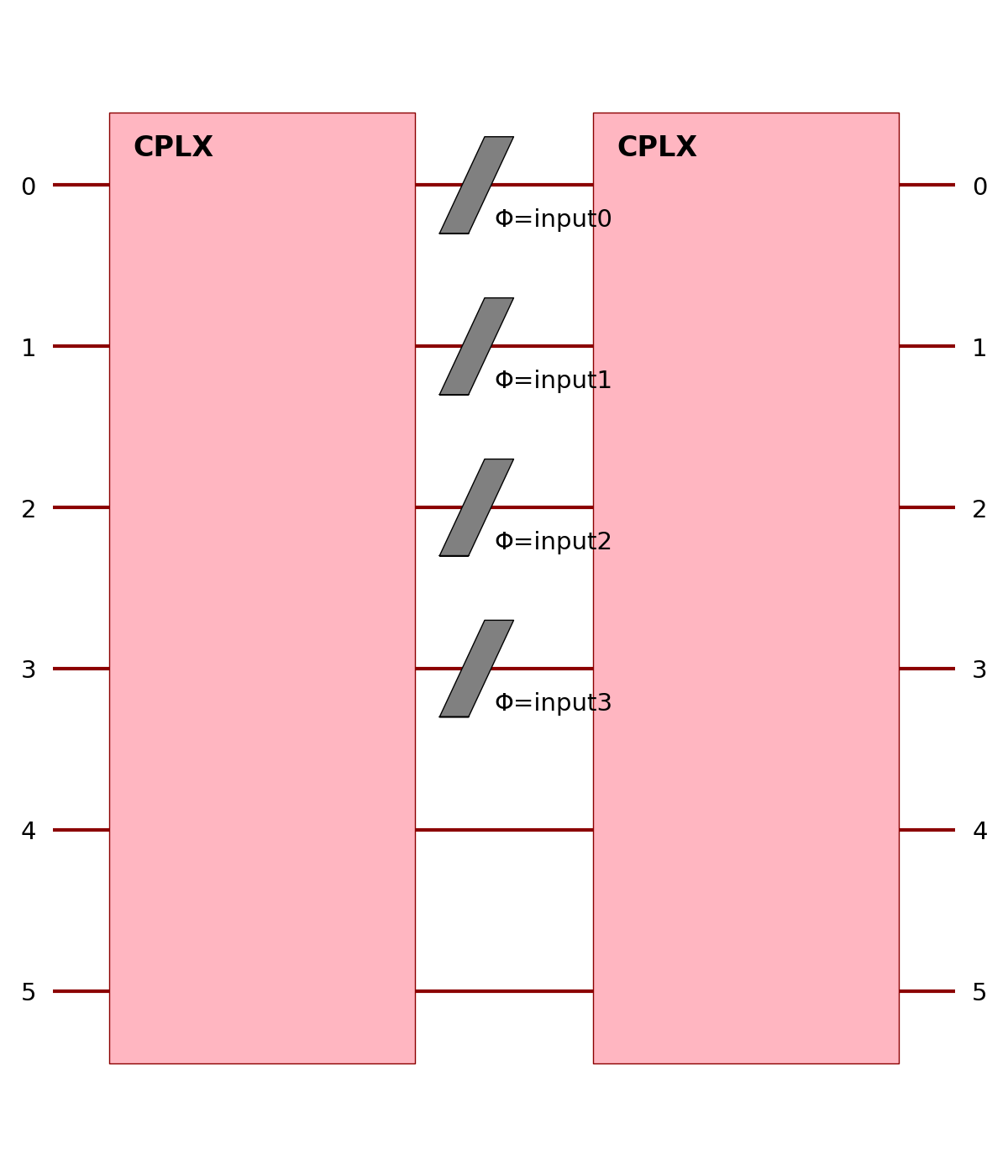
Here, the grouping can also be directly added to the MeasurementStrategy object used in the measurement_strategy parameter.
See the User guide and Notebooks for more advanced usage and training routines !
Input states and amplitude encoding
The input state of a photonic circuit specifies how the photons enter the device. Physically this can be a single
Fock state (a precise configuration of n_photons over m modes) or a superposed/entangled state within the same
computation space (for example Bell pairs or GHZ states). QuantumLayer accepts the
following representations:
pcvl.BasicState – a single configuration such as
pcvl.BasicState([1, 0, 1, 0]);StateVector– an arbitrary superposition of basic states with complex amplitudes;- Python lists/tuples, e.g.
[1, 0, 1, 0]. These are accepted as convenience inputs and are immediately converted to a Perceval perceval.BasicState.
- Python lists/tuples, e.g.
Note
For Fock/occupation inputs, QuantumLayer stores .input_state as a Perceval
pcvl.BasicState. If you need the raw occupation vector, use list(layer.input_state).
When input_state is passed, the layer always injects that photonic state. In more elaborate pipelines you may want
to cascade circuits and let the output amplitudes of the previous layer become the input state of the next. Merlin
calls this amplitude encoding: the probability amplitudes themselves carry information and are passed to the next
layer as a tensor. Enabling this behaviour is done with amplitude_encoding=True; in that mode the forward input of
QuantumLayer is the complex photonic state.
The snippet below prepares a dual-rail Bell state as the initial condition and evaluates a batch of classical parameters:
import torch
import perceval as pcvl
from merlin.algorithms.layer import QuantumLayer
from merlin.core import ComputationSpace
from merlin.measurement.strategies import MeasurementStrategy
from merlin.measurement.
circuit = pcvl.Unitary(pcvl.Matrix.random_unitary(4)) # some haar-random 4-mode circuit
bell = pcvl.StateVector()
bell += pcvl.BasicState([1, 0, 1, 0])
bell += pcvl.BasicState([0, 1, 0, 1])
print(bell) # bell is a state vector of 2 photons in 4 modes
layer = QuantumLayer(
circuit=circuit,
n_photons=2,
input_state=bell,
measurement_strategy=MeasurementStrategy.probs(computation_space=ComputationSpace.DUAL_RAIL),
)
x = torch.rand(10, circuit.m) # batch of classical parameters
amplitudes = layer(x)
assert amplitudes.shape == (10, 2**2)
For comparison, the amplitude_encoding variant supplies the photonic state during the forward pass:
import torch
import perceval as pcvl
from merlin.algorithms.layer import QuantumLayer
from merlin.core import MeasurementStrategy,ComputationSpace
circuit = pcvl.Circuit(3)
layer = QuantumLayer(
circuit=circuit,
n_photons=2,
amplitude_encoding=True,
measurement_strategy=MeasurementStrategy.probs(computation_space=ComputationSpace.UNBUNCHED),
dtype=torch.cdouble,
)
prepared_states = torch.tensor(
[[1.0 + 0.0j, 0.0 + 0.0j, 0.0 + 0.0j],
[0.0 + 0.0j, 0.0 + 0.0j, 1.0 + 0.0j]],
dtype=torch.cdouble,
)
out = layer(prepared_states)
In the first example the circuit always starts from bell; in the second, each row of prepared_states represents a
different logical photonic state that flows through the layer. This separation allows you to mix classical angle
encoding with fully quantum, amplitude-based data pipelines.
Returning typed objects
When return_object is set to True, the output of a forward() call depends of the measurement_strategy. By default,
it is set to False. See the following output matrix to see what to expect as the return of a forward call.
measurement_strategy |
return_object=False |
return_object=True |
|---|---|---|
AMPLTITUDES |
torch.Tensor |
StateVector |
PROBABILITIES |
torch.Tensor |
ProbabilityDistribution |
PARTIAL_MEASUREMENT |
PartialMeasurement |
PartialMeasurement |
MODE_EXPECTATIONS |
torch.Tensor |
torch.Tensor |
Most of the typed objects can give the torch.Tensor as an output with the .tensor parameter. Only the
PartialMeasurement object is a little different. See its according documentation.
These object could be quite useful to access metadata like the number of photons, modes and measurement_strategy behind the output tensors. For example, a better access to specific
states is available with StateVector and ProbabilityDistribution by indexing the desired state. The objects are interoperable with Perceval, enabling seamless interaction between the two libraries.
For more information on the typed output capabilities, follow the following links:
The snippet below prepares a basic quantum layer and returns a ProbabilityDistribution object:
import torch
import perceval as pcvl
from merlin.algorithms.layer import QuantumLayer
from merlin.core import ComputationSpace, ProbabilityDistribution
from merlin.measurement.strategies import MeasurementStrategy
circuit = ML.CircuitBuilder(n_modes=4)
circuit.add_entangling_layer()
bell = pcvl.StateVector()
bell += pcvl.BasicState([1, 0, 1, 0])
bell += pcvl.BasicState([0, 1, 0, 1])
print(bell) # bell is a state vector of 2 photons in 4 modes
layer = QuantumLayer(
builder=circuit,
n_photons=2,
input_state=bell,
measurement_strategy=MeasurementStrategy.probs(computation_space=ComputationSpace.DUAL_RAIL),
return_object=True,
)
x = torch.rand(10, circuit.m) # batch of classical parameters
probs = layer(x)
assert isinstance(probs,ProbabilityDistribution)
assert isinstance(probs.tensor,torch.Tensor)
Deprecations
Warning
Deprecated since version 0.3:
The use of the no_bunching flag is deprecated and is removed since version 0.3.0.
Use the computation_space flag inside measurement_strategy instead. See Migration guide.