Neural Quantum Embedding: Pushing the Limits of Quantum Supervised Learning
Paper Information
Title: Neural Quantum Embedding: Pushing the Limits of Quantum Supervised Learning
Authors: Tak Hur, Israel F. Araujo and Daniel K. Park
Published: APS journals, Phys. Rev. A 110, 022411, (2024)
DOI: https://arxiv.org/abs/2311.11412
Reproduction Status: ✅ Complete
Reproducer: Louis-Félix Vigneux (louis-felix.vigneux@quandela.com)
Project Repository
Abstract
This paper introduces a QPU efficient way to encode classical data by training the embeddings. This methods, proven mathematically, enables the encoding of the data to be maximally distant on the quantum Hilbert space. It also states that the rest of the trainable circuit can not improve that embedding and can just find an optimal measurement limited by the representation of the data.
Significance
An optimal encoding makes the classification of the data easier. As it is showed in the paper, a bad encoding can severely limit the performance of the model if it is not appropriate. The performance of an embedding varies on the dataset. Hence, a variable encoding may be the optimal way to classify the data. The classifier part of a QML algorithm only finds the optimal measurement that is clearly limited by the encoded states.
MerLin Implementation
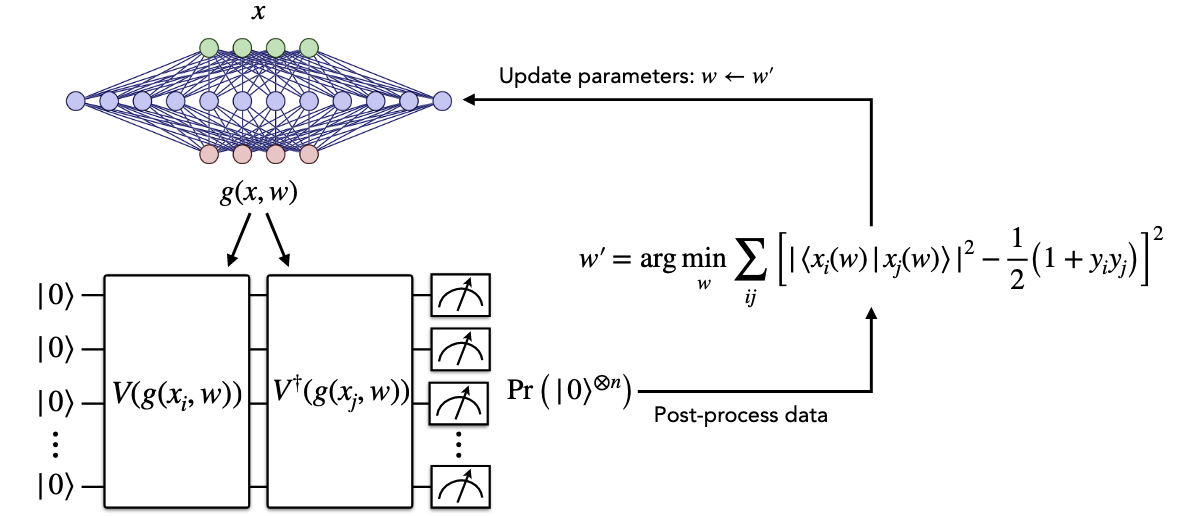
The NQE framework is a training paradigm for quantum models designed to optimize the embedding process and, consequently, improve the overall classifier performance. The NQE model consists of three main components:
The classical model: Processes the input data and converts it into phase parameters for the quantum embedder.
The quantum embedder: Encodes quantum states based on the output produced by the classical model.
The quantum classifier: Performs classification on the quantum states generated by the embedder.
The training process begins by optimizing the classical model to produce quantum encodings that are maximally separated in the embedding space. Once this stage is complete, the quantum classifier is trained in the same manner as a standard quantum model.
The MerLin implementation was not trivial to implement since the relation between input and trainable parameters in the NQE scenario was obscure. Indeed, the embedding circuit of the NQE must receive its parameters from the classical model. However, if we want to use a general interferometer to encode the data with MerLin, the parametrized phase shifters are considered as trainable parameters and not input ones. We chose to restrict the quantum encoder to have only trainable parameters and no input that the classical model will modify. It seemed like a more natural interpretation since we want to “train” the parameters of the quantum embedder. However, that required some workarounds in MerLin to assign the parameter values as model parameters and not input.
The same results are observed with the gate-based version (in PennyLane) and MerLin-based version with the MerLin version seeming more efficient time-wise.
Key Contributions Reproduced
- The encoding strategy limits the model’s performance
The encoding strategy delimits a loss plateau of the model.
The optimal encoding strategy, found with NQE, creates the best model (a lower loss and better accuracy is achieved).
Implementation Details
import merlin as ml
# Example code showing key implementation
builder = ml.CircuitBuilder(n_modes=[number])
builder.add_entangling_layer(name="phi_")
builder.add_rotations(role="input", name="pl", axis="z")
builder.add_entangling_layer(name="phi_")
circuit = builder.to_pcvl_circuit()
# Additional setup code
model = ml.[ModelType](
circuit=circuit,
parameter1=value1,
parameter2=value2
)
Experimental Results
To see the result plots, consult the ReadMe of the project.
Technical Implementation Details
The workflow is command-line driven:
# HQNN sweep
python implementation.py --paper nn_embedding
consult the ReadMe for more instructions and the CLI file for all possible configurations.
Performance Analysis
- Advantages of the approach
Lowest loss is achieved with the NQE
Interoperability with MerLin QuantumLayer
Interactive Exploration
Jupyter Notebook: Neural Quantum Embedding: Pushing the Limits of Quantum Supervised Learning (nn_embedding)
The provided notebook shows how to run the MerLin NQE implementation.
Extensions and Future Work
This paper was reproduced in order to have an “optimal encoding” in an embedding study.
Code Access and Documentation
GitHub Repository: merlin/reproductions/nn_embedding
The complete implementation includes:
The MerLin based implementation of the NQE framework
The Pennylane gate-based implementation of the NQE framework
Figure reproduction methods
Tutorial notebook
Citation
@article{hur_neural_2024,
title = {Neural {Quantum} {Embedding}: {Pushing} the {Limits} of {Quantum} {Supervised} {Learning}},
volume = {110},
issn = {2469-9926, 2469-9934},
shorttitle = {Neural {Quantum} {Embedding}},
url = {http://arxiv.org/abs/2311.11412},
doi = {10.1103/PhysRevA.110.022411},
number = {2},
urldate = {2026-03-09},
journal = {Physical Review A},
author = {Hur, Tak and Araujo, Israel F. and Park, Daniel K.},
month = aug,
year = {2024},
note = {arXiv:2311.11412 [quant-ph]},
keywords = {Quantum Physics, Computer Science - Emerging Technologies},
pages = {022411},
}
Impact and Applications
The method demonstrated in this reproduction has implications for:
Encodings: This embedding strategy can be useful when usual strategies such as amplitude or angle encoding fail. This framework is general and allow for custom made models to be passed and trained directly.