Photonic QGAN GPU Performance
This benchmark measures the
photonic QGAN-style generator path implemented with
PhotonicGenerator. It measures the
generator forward pass, the backward pass through output.square().mean(),
and PyTorch CUDA allocator pressure. It does not train a discriminator and does
not measure generated-image quality.
Benchmark setup
Field |
Value |
|---|---|
GPU |
NVIDIA H100 PCIe, 80 GB class, 114 streaming multiprocessors |
Runtime |
Python 3.12.3, PyTorch 2.9.1+cu128, Linux 6.8.0-87 |
Precision |
|
Timing protocol |
2 warmup steps, then 5 measured repetitions per case |
Quantum layer |
MZI entangling layer, angle encoding, 1 trainable variational layer |
Latent dimension |
4 |
Default image shape |
|
Measured computation spaces |
|
Here, system size means the number of basis states in the selected computation space for the given photon and mode count.
The benchmark records two memory views:
Peak allocated CUDA memoryThe maximum absolute value reported by
torch.cuda.memory_allocated()during the measured forward or backward pass.Peak allocated deltaThe maximum increase above the memory already allocated at the start of the measured forward or backward pass. This is the best estimate of incremental memory pressure for one operation.
Summary
Case |
Space |
System size |
Batch |
Heads |
Forward |
Backward |
|---|---|---|---|---|---|---|
|
|
490,314 |
8 |
1 |
82.25 ms |
138.96 ms |
|
|
8,855 |
8 |
8 |
848.95 ms |
1,437.91 ms |
|
|
2,220,075 |
8 |
1 |
193.35 ms |
328.07 ms |
|
|
125,970 |
8 |
1 |
106.18 ms |
176.99 ms |
|
|
8,855 |
8 |
1 |
101.39 ms |
170.85 ms |
Case |
Setup allocated |
Peak allocated |
Peak allocated delta |
|---|---|---|---|
|
153.9 MiB |
1,404.2 MiB |
927.5 MiB |
|
72.8 MiB |
148.9 MiB |
68.4 MiB |
|
473.7 MiB |
6,272.1 MiB |
4,232.5 MiB |
|
107.4 MiB |
650.8 MiB |
424.1 MiB |
|
65.1 MiB |
79.3 MiB |
10.5 MiB |
Main observations
The largest measured Fock-space case,
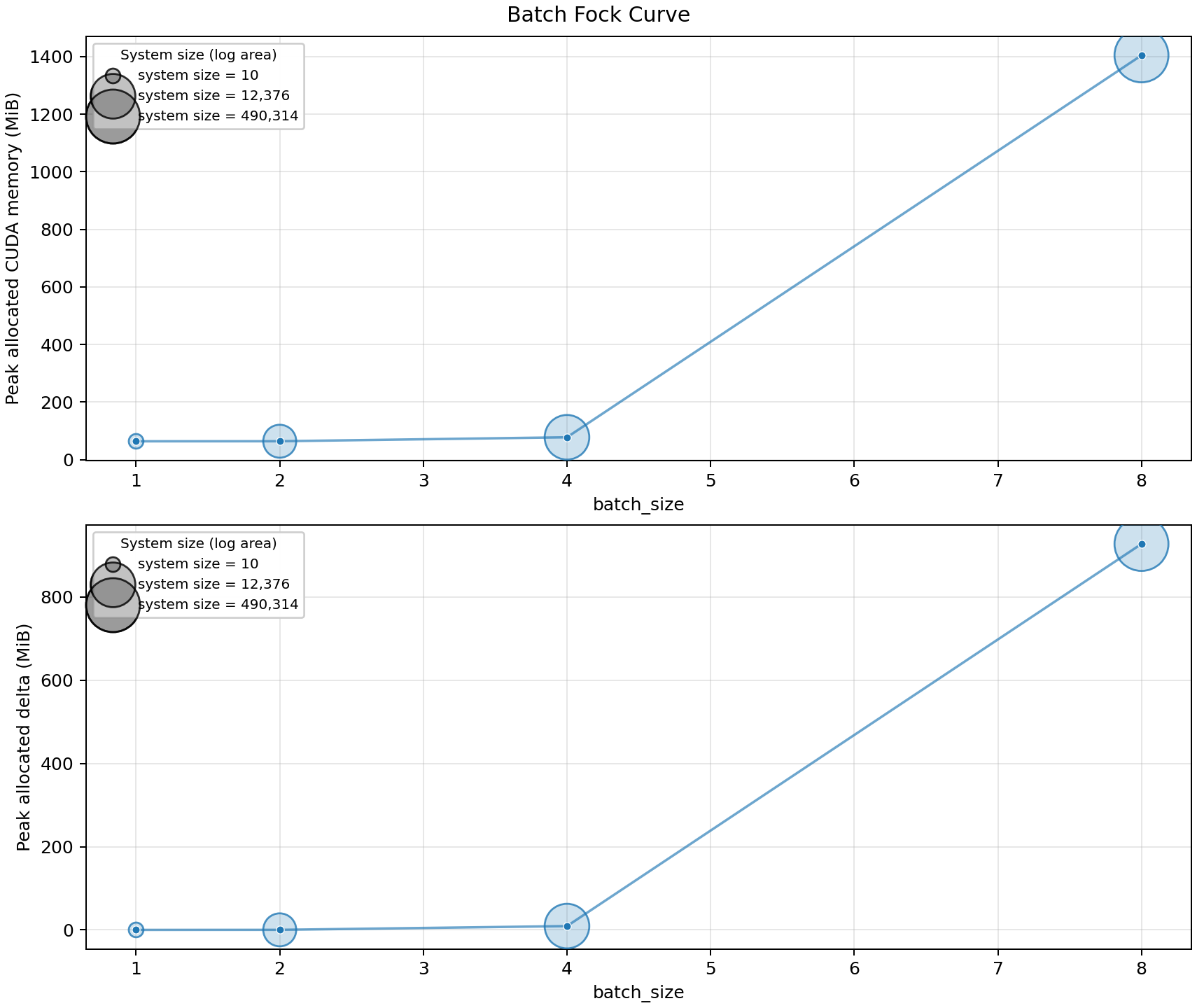
20modes and8photons, reaches a system size of 2,220,075 and needs 4,232.5 MiB of incremental allocated CUDA memory during the measured operation.For the same
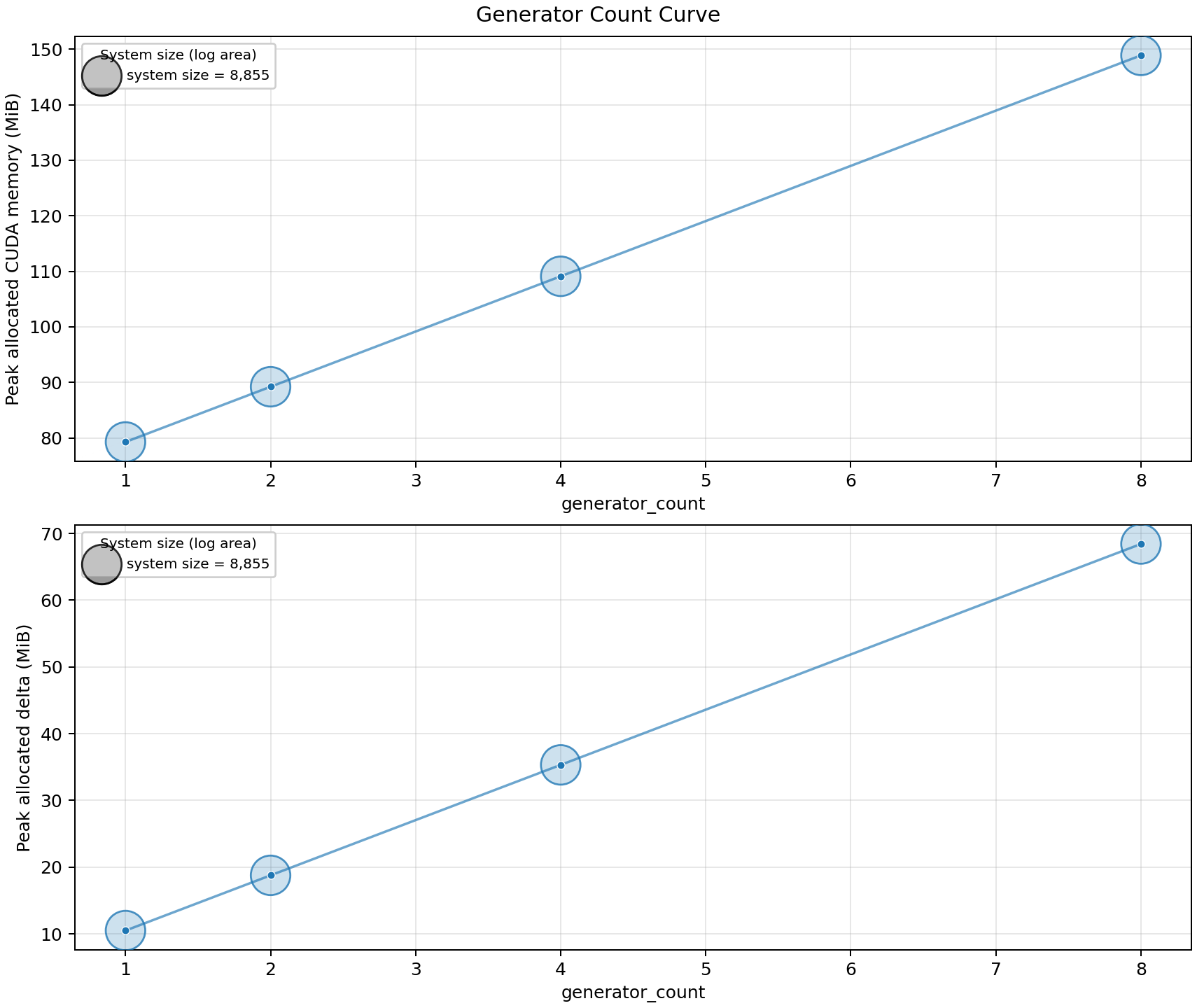
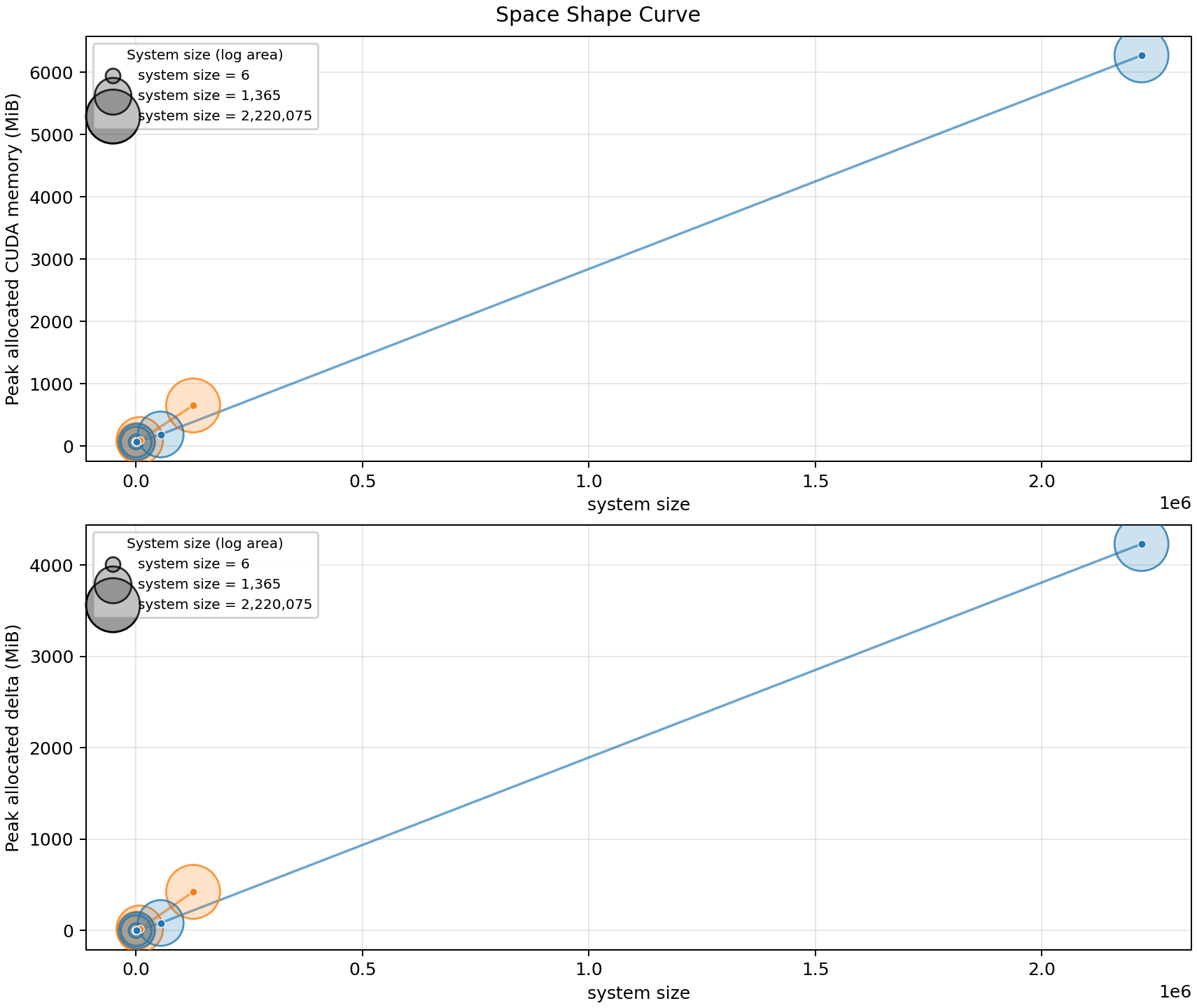
20modes and8photons, switching fromFOCKtoUNBUNCHEDreduces the system size from 2,220,075 to 125,970 and reduces the measured incremental allocation from 4,232.5 MiB to 424.1 MiB.Increasing the number of generator heads from
1to8is close to linear in runtime for the fixed20mode,4photon setup. Forward time grows from 101.27 ms to 848.95 ms and backward time grows from 171.27 ms to 1,437.91 ms.Increasing the image adapter output from
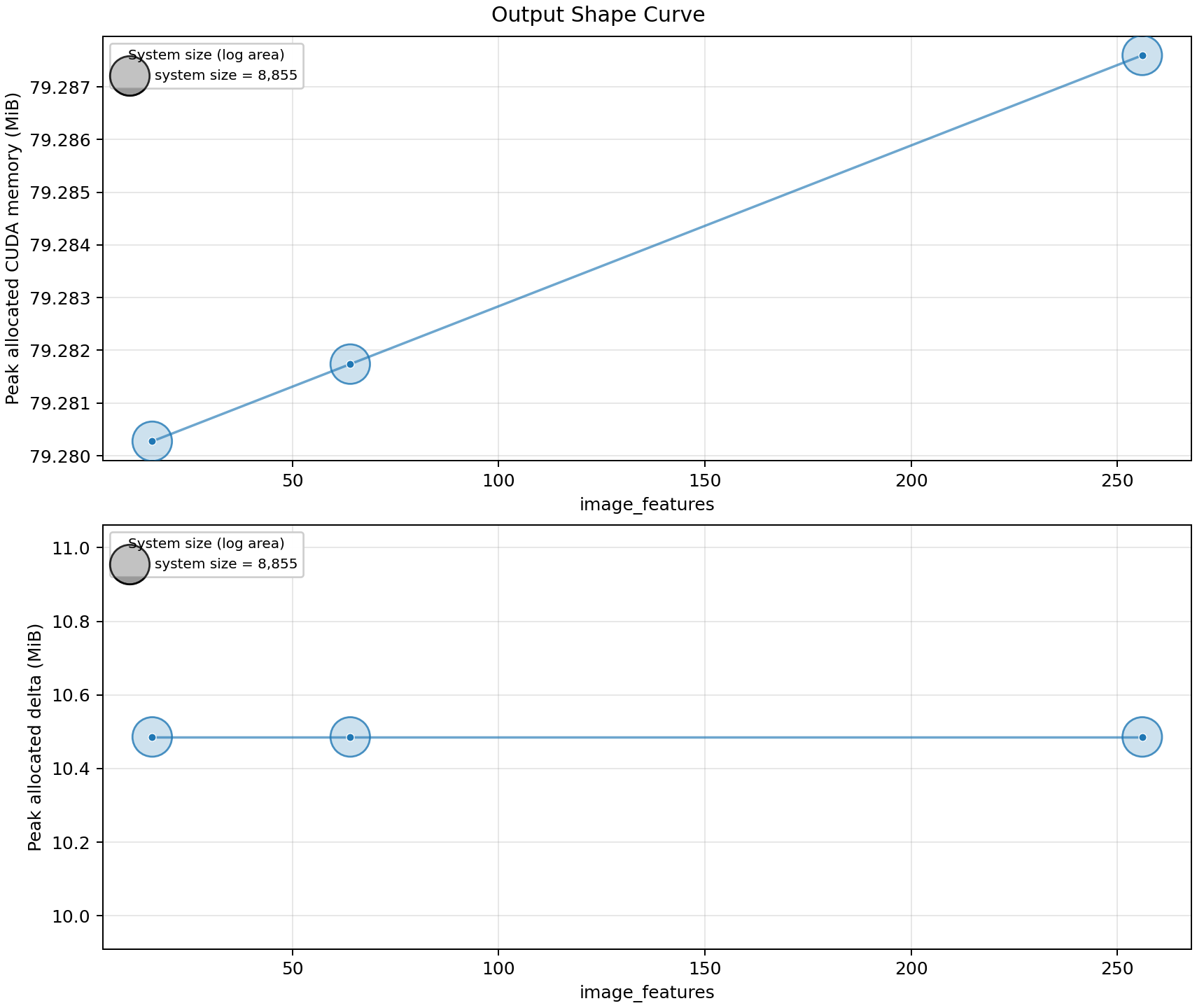
1x4x4to1x16x16does not change the measured quantum runtime or memory materially when the quantum layer and system size are fixed. This sweep measures adapter/runtime cost only.
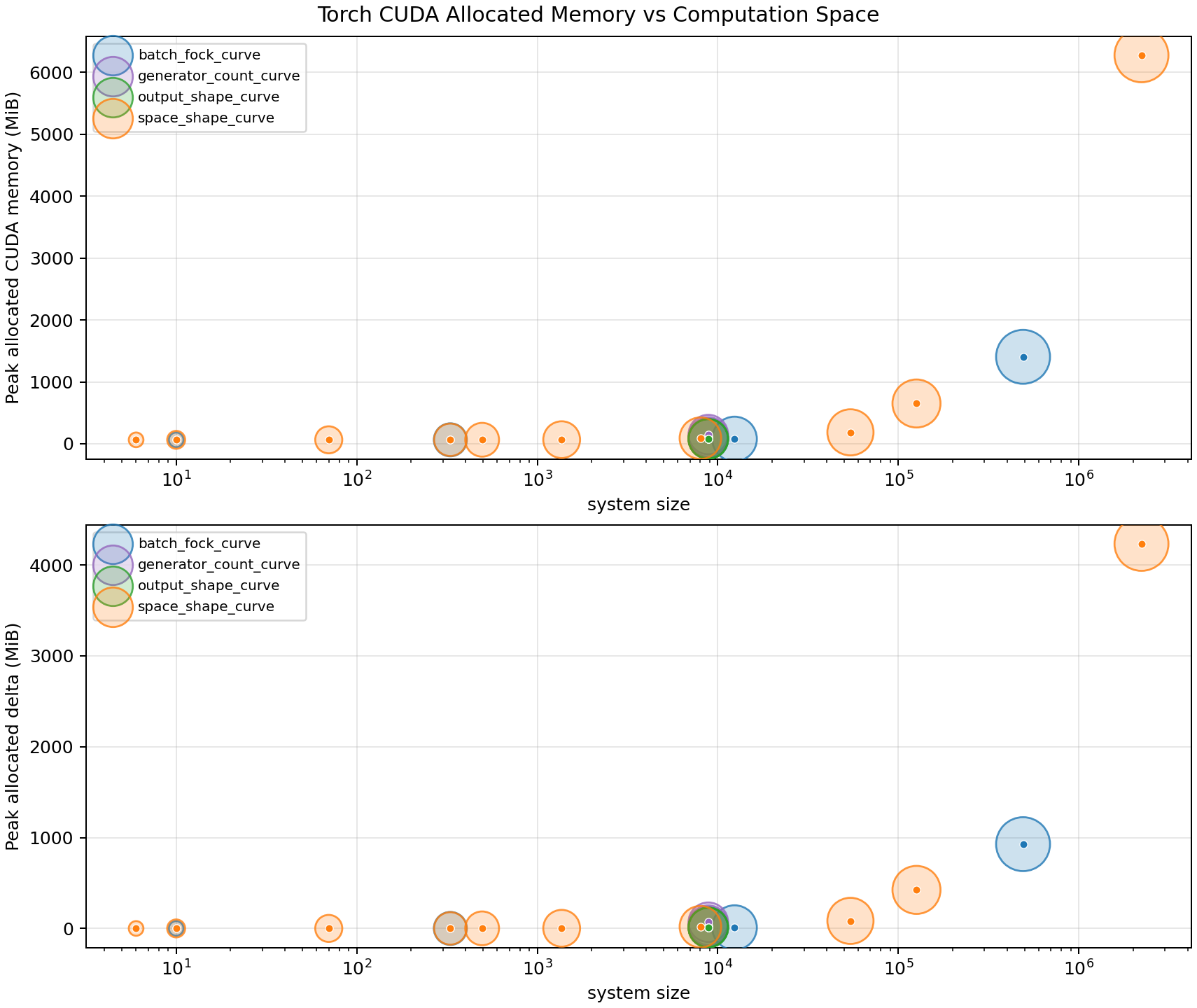
Memory overview
The marker area is proportional to computation-space system size, using a logarithmic area scale.
Batch and Fock-space scaling
This sweep uses FOCK with n_modes = 2 * n_photons and increases
batch_size from 1 to 8.
Generator-head scaling
This sweep fixes 20 modes, 4 photons, FOCK space, batch size 8,
and image shape 1x4x4 while increasing the number of generator heads.
Computation-space scaling
This sweep compares FOCK and UNBUNCHED spaces for the same mode and
photon counts.
Output-shape scaling
This sweep fixes the quantum layer and changes only the image adapter output shape.
Reproducing the benchmark
Run the CUDA benchmark from the repository root. The --plot-dir argument
writes the timing plots and the allocated-memory graphs shown above.
PYTHONPATH=$PWD PCVL_PERSISTENT_PATH=.pcvl_home \
python benchmarks/benchmark_photonic_generator_gpu.py \
--json-out benchmarks/results/photonic_generator_gpu.json \
--plot-dir docs/source/_static/img/performance/qgan
Regenerate the memory graphs from an existing JSON output without rerunning the CUDA benchmark:
PYTHONPATH=$PWD python benchmarks/benchmark_photonic_generator_gpu.py \
--json-in benchmarks/results/photonic_generator_gpu.json \
--plot-dir docs/source/_static/img/performance/qgan